21
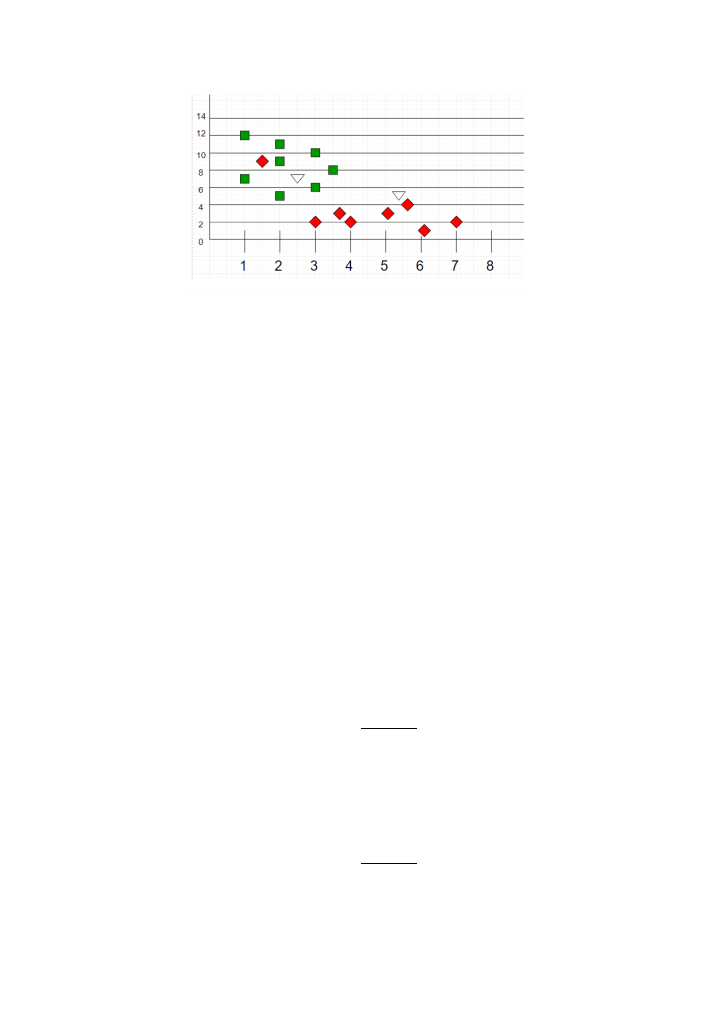
Figure 4: knn during testing
K- nearest neighbours is a good algorithm to use when the data is multinomial (multiple
classes), or non-linear (for regression problems), since it doesn’t have underlying assumptions
on the training data distribution; it is also easy to understand and implement. However, the
computational cost and memory requirements are relatively high, as it must store all the
training data to work, and if the value of 𝑘 is high, then the voting process takes much longer
to predict the outcome.
3.4. Gaussian Naïve Bayes
Naïve Bayes is a probabilistic classification algorithm based on the Bayes theorem. Gaussian
NB is an extension of it, which assumes Gaussian (normal) distribution of the data. The naivety
of the model comes from the assumption that all the features of the dataset are independent
from each other, meaning that variation in one variable of the dataset do not impact the other
features. The Bayes theorem is a conditional probability theorem that defines a classifier so
that the error rate (misclassification) is minimized through the training phase, that works in a
way to go from 𝑃(𝑋|𝑌) to find 𝑃(𝑌|𝑋) [19][20].
In the Bayes rule, from the training data we have:
𝑃(𝑋|𝑌) =
𝑃(𝑋 ∩ 𝑌)
𝑃(𝑌)
Equation 3: probability that X belongs to class Y
And from this, which is learnt during training, the model needs to learn the opposite (if 𝑌 is the
correct class), during the testing phase:
𝑃(𝑌|𝑋) =
𝑃(𝑋 ∩ 𝑌)
𝑃(𝑋)
Equation 4: probability that class Y is the correct outcome of occurrence X