20
outcomes of the classification process, when the model cannot further classify the subset that
has gone that way. Another process for correcting the model and minimizing error is pruning,
which cuts out the branches that don’t have any data and keeps the optimal tree paths [16].
The decision tree is a simple algorithm that mimics the way humans make decisions, so it can
be very useful in decision-related problems, and its simplicity also requires less cleaning and
preparing for the data. However, when the dataset contains many labels, the classifier is prone
to overfitting, and its complexity becomes very high when there are many layers to the
decisions.
3.3. K – Nearest Neighbours
K nearest neighbours is one of the most essential supervised classification algorithms in
machine learning. It is also one of the most basic ones, given that it doesn’t make any
assumptions about the distribution of the data (non-parametric algorithm). It finds application
in pattern recognition, intrusion detection and data mining [17], [18].
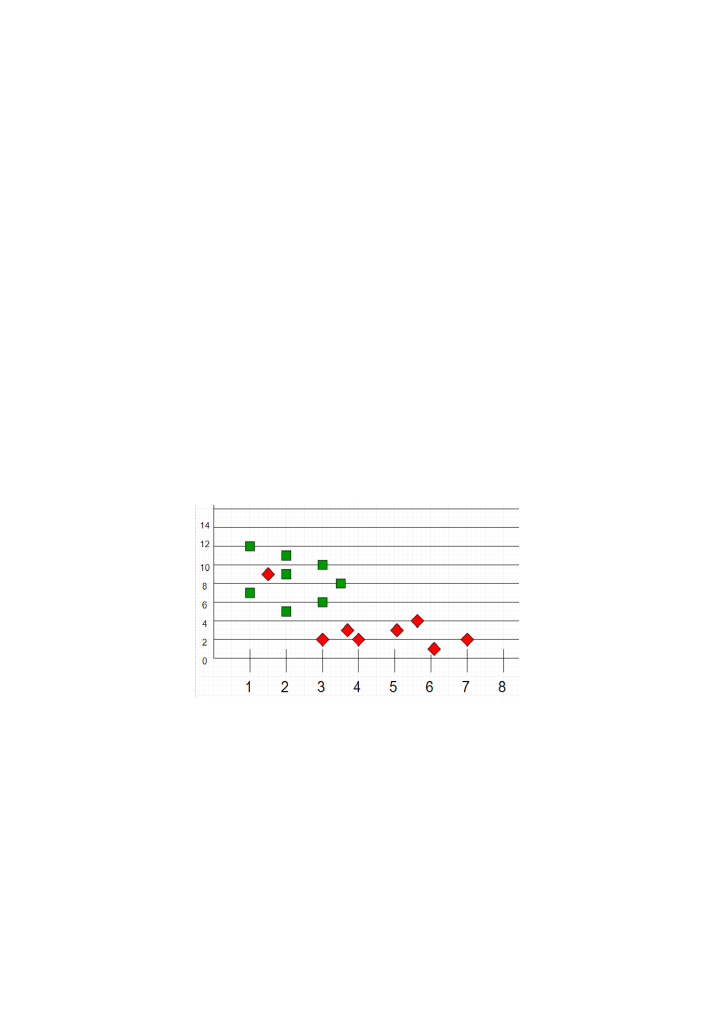
As a supervised method, the training set is first distributed according to the labels in a 𝑛
dimensional space (as the vector of the input features enforces), like we can see the two labels
(“Green”/“Red”) in
Figure 3: knn distribution of the training set according to its labels (source
[17]
)
After that, during the testing, unclassified data is placed in the graph according to their
attributes, and the model must try to classify it properly (
). This is where the parameter
𝑘 plays an important role, as this algorithm determines the class of each test datapoint as the
same class that the majority of its 𝑘- nearest neighbours are, through a voting mechanism. If
we set 𝑘 = 1, then the unclassified datapoint will be grouped together with its closest
classified point. In general, when we choose fewer neighbours, it is better to choose an odd
number of them, so that there is no conflict to resolve.